 Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinMaximize Inference Throughput Under Power Constraints: A Cross-Layer Strategy
Learn how cross-layer coordination—power, cooling, scheduling—unlocks stranded data center capacity for AI inference. By prioritizing latency-tolerant workloads, operators can gain boost throughput.
As inference workloads transition to represent 75-80% of data center compute by 2028, power constraints have become the primary bottleneck to AI deployment. Yet operational facilities leave 50-70% of provisioned power unused while GPUs running inference average just 7-28% utilization. Massive stranded capacity exists because power distribution, thermal management, and compute scheduling optimize independently without coordination.
Companies that are tackling the data center energy crisis are designed to address this gap by coordinating cooling, power, workload placement, and GPU operating points so operators can convert 'stranded' facility headroom into usable inference throughput under a fixed power cap.
Cross-layer evaluation coordination, has found that coordinating infrastructure a
nd scheduling decisions can unlock 30% additional GPU capacity under fixed power budgets, with only modest latency increases for tolerant workloads. This article examines how coordinating decisions across infrastructure layers transforms stranded capacity into usable inference throughput.
The Inference Power Paradox
Industry analyses project that inference will account for 75-80% of AI compute by 2028, with demand growing at 40-50% compound annual rates. Yet U.S. data center electricity consumption is projected to reach 6-12% of national demand by 2028, with utility interconnection delays stretching up to seven years.
Despite this scarcity, empirical data reveals profound underutilization. UK Power Networks found data centers using only 30-40% of connected capacity, with mean utilization averaging 21-28% across 89 facilities. Production traces from Alibaba's inference platform show GPU mean utilization around 7% across active containers, with most operational time below 30% even during live serving.

Figure 1. The inference power paradox
The root cause is siloed optimization: power systems provision statically for peak demand, compute schedulers maximize placement without power awareness, and cooling operates on temperature thresholds divorced from workload characteristics. Each layer optimizes locally while the global system leaves capacity unused.
Why Inference Enables Cross-Layer Optimization
Inference workloads possess characteristics that create optimization opportunities unavailable in training. Training exhibits sustained, predictable GPU utilization at thermal design power for hours or days. Inference demonstrates variable, bursty consumption with clear valleys between request peaks.
More critically, inference workloads span a wide latency tolerance spectrum.
- Latency-critical applications: conversational agents
- Real-time ranking
- Require sub-500ms responses where violations degrade user experience
- Automated driving and robotic applications
Latency-tolerant workloads that can absorb seconds to minutes of scheduling flexibility without business impact
- Batch video generation
- Large-scale summarization
- RAG
- Fine-tuning

Figure 2. Latency spectrum for inference workloads
This heterogeneity creates opportunity: by aligning latency-tolerant workloads with infrastructure headroom and applying power-aware orchestration, operators can increase total inference throughput per megawatt while staying within existing limits.
A Cross-Layer Optimization Framework
Maximizing inference capacity under power constraints requires coordination across two complementary layers validated in production deployments.
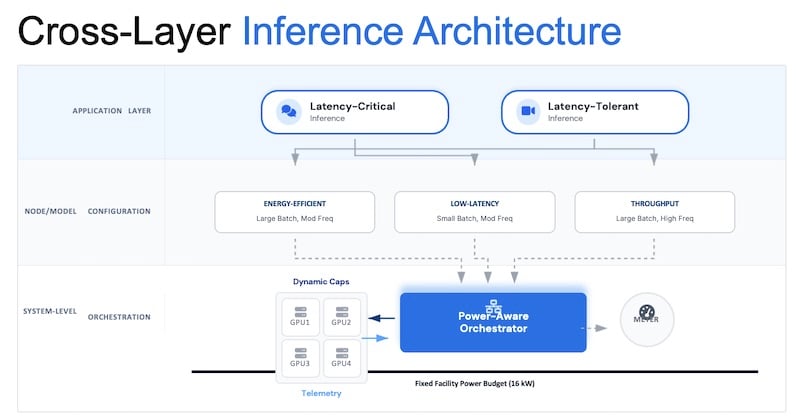
Figure 3. Cross-layer architecture diagram
Layer 1: Model and Node-Level Efficiency
GPU serving parameters (batch size and operating frequency) create a three-dimensional trade-off surface between energy efficiency (tokens per joule), latency, and throughput.
Empirical analysis of large language model inference reveals three distinct operating modes:
- Energy-Efficient Mode (large batch, moderate frequency): Maximizes tokens per joule, suitable for batch analytics where latency is secondary.
- Low-Latency Mode (small batch, moderate frequency): Minimizes time-between-tokens for interactive applications. Counterintuitively, operating at moderate rather than maximum frequency often provides minimal latency penalty while significantly reducing power consumption.
- Throughput-Driven Mode (large batch, high frequency): Maximizes tokens per second for high-volume API serving, at the cost of highest power draw.
No single configuration optimizes all three objectives simultaneously. Operators must select modes aligned with workload requirements, understanding that each choice constrains both the per-GPU power envelope and facility-wide power budget.
Layer 2: System-Level Power-Aware Orchestration
Individual GPU optimization is insufficient when multiple workloads share a facility power allocation. Consider a data center with 1.6 MW grid allocation running a cluster of GPUs at 1.56 MW baseline draw, leaving only 400W headroom. Adding additional GPU nodes without coordination causes aggregate power to breach the facility cap, triggering throttling and instability.
Companies that are tackling the data center energy crisis address this at the system level by enforcing a facility-wide power budget in real time and preferentially shaping latency-tolerant inference work when aggregate consumption approaches the cap
Power-aware orchestration solves this through real-time control:
- Continuous monitoring: Sample per-GPU power at 1Hz intervals and aggregate cluster-wide consumption
- Threshold-based decisions: When aggregate power approaches the facility cap, identify candidate GPUs serving latency-tolerant workloads
- Dynamic actuation: Apply power caps to selected GPUs via software interfaces, reducing frequency and power draw
- Feedback control: Monitor whether aggregate power stabilizes; adjust based on workload patterns
Production validation on text-to-video inference demonstrates the economic trade-off at production scale. Using an orchestrated control with a fixed power cap:
- Baseline configuration: Operating at 97.5% of power cap with baseline median job completion time
- Orchestrated: 30% additional GPU capacity deployed at 98.75% of power cap (below threshold) with 10-25% median completion time increase
This delivers 30% more GPU capacity with minimal latency increase for tolerant workloads. Accounting for latency impact, effective throughput increases approximately 18-20% within the same power budget. Power stability improves dramatically and time spent above the facility cap drops from 40-60% (unmanaged) to under 5% (orchestrated), eliminating thermal throttling and admission control failures.

Figure 4. Comparison of baseline vs orchestrated operation
Integrating the Layers
The true power emerges when combining both optimization layers. Orchestration systems can dynamically adjust batch size and GPU frequency per workload.
When aggregate power approaches facility limits, the system might:
- Shift latency-tolerant GPUs from throughput mode to energy-efficient mode, freeing power headroom while maintaining acceptable latency
- Keep latency-critical GPUs in low-latency mode at full power, protecting user-facing SLAs
- Rebalance configurations as workload mix evolves, maximizing facility-wide tokens per watt of provisioned capacity
This hierarchical approach enables operators to extract maximum inference value from existing infrastructure.
The Path Forward
Evidence from production deployments validates that the fastest route to additional AI capacity is unlocking stranded power in existing data centers, not building new facilities. If the industry activates even 20-30% of documented stranded capacity through cross-layer coordination, it represents hundreds of terawatt-hours of inference serving potential without new power plants or grid connections.
As inference becomes the dominant AI workload in a power-constrained world, competitive advantage shifts to operators who can coordinate decisions across power, cooling, and compute around actual inference behavior. Modern GPUs support fine-grained power management, inference frameworks increasingly expose workload metadata and latency SLAs, and orchestration platforms can tie these capabilities together in real-time control loops.
The facilities, GPUs, and power infrastructure already exist. The question is whether the industry will build the intelligence to use them effectively. Cross-layer optimization represents the transition from capacity acquisition to capacity productivity, turning today's power constraints into tomorrow's inference advantage. Practically, that means deploying a power-aware orchestration layer that can start with monitoring and policy-only recommendations, then graduate to closed-loop actuation as operators gain confidence in stability and SLA outcomes.
All images used courtesy of Hammerhead AI.











